


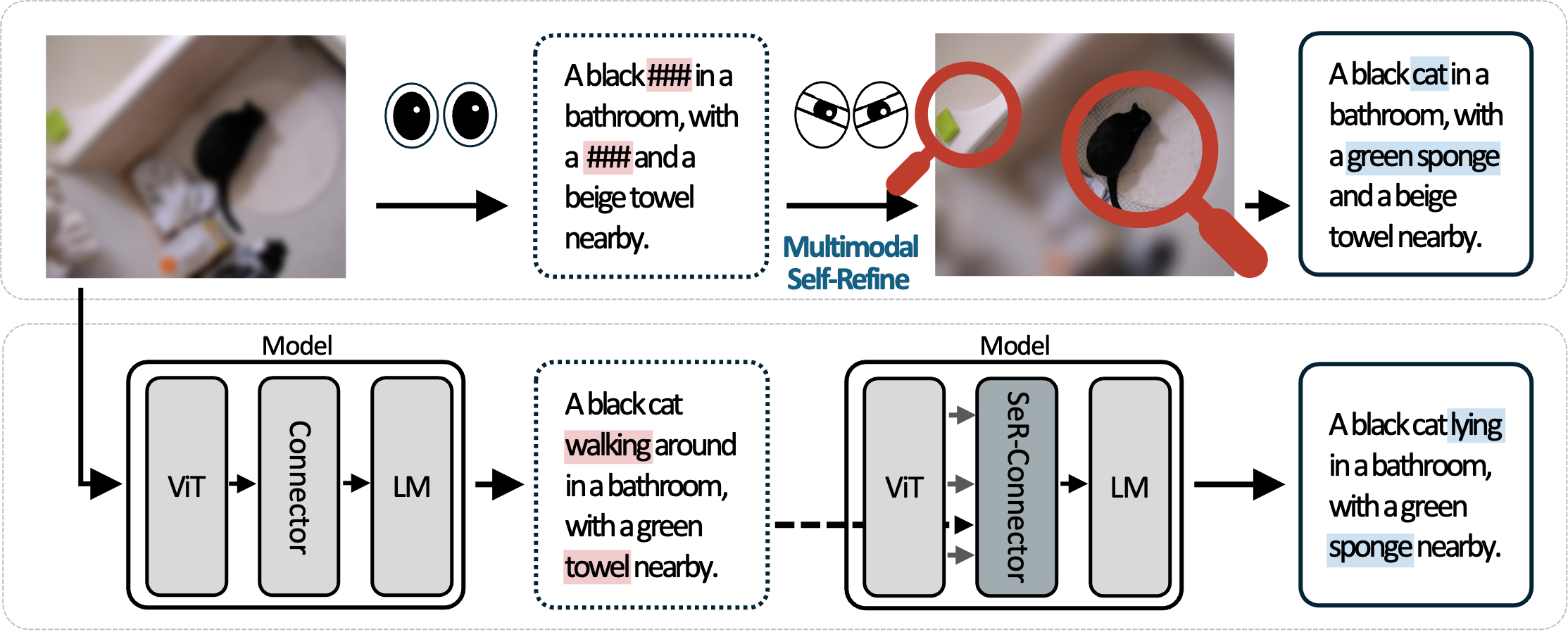

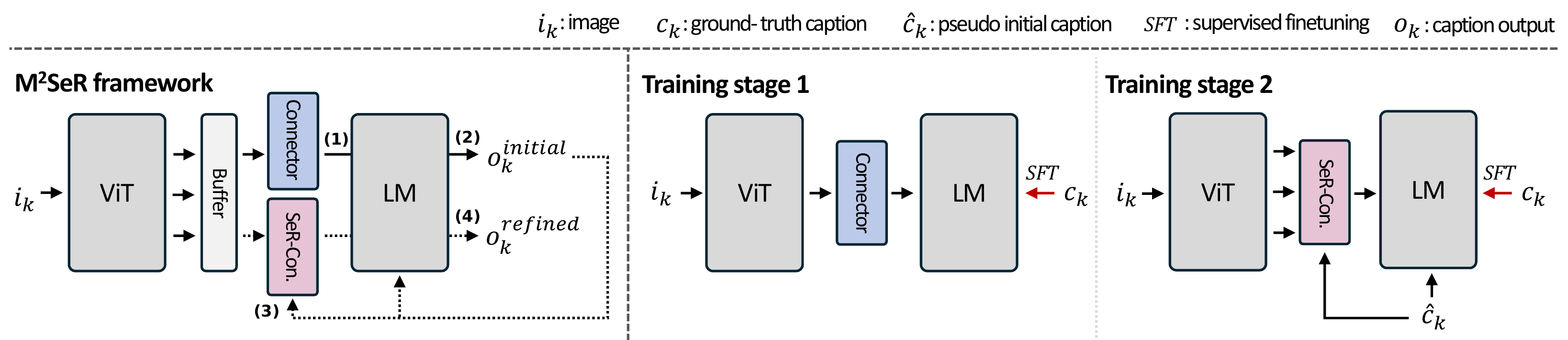
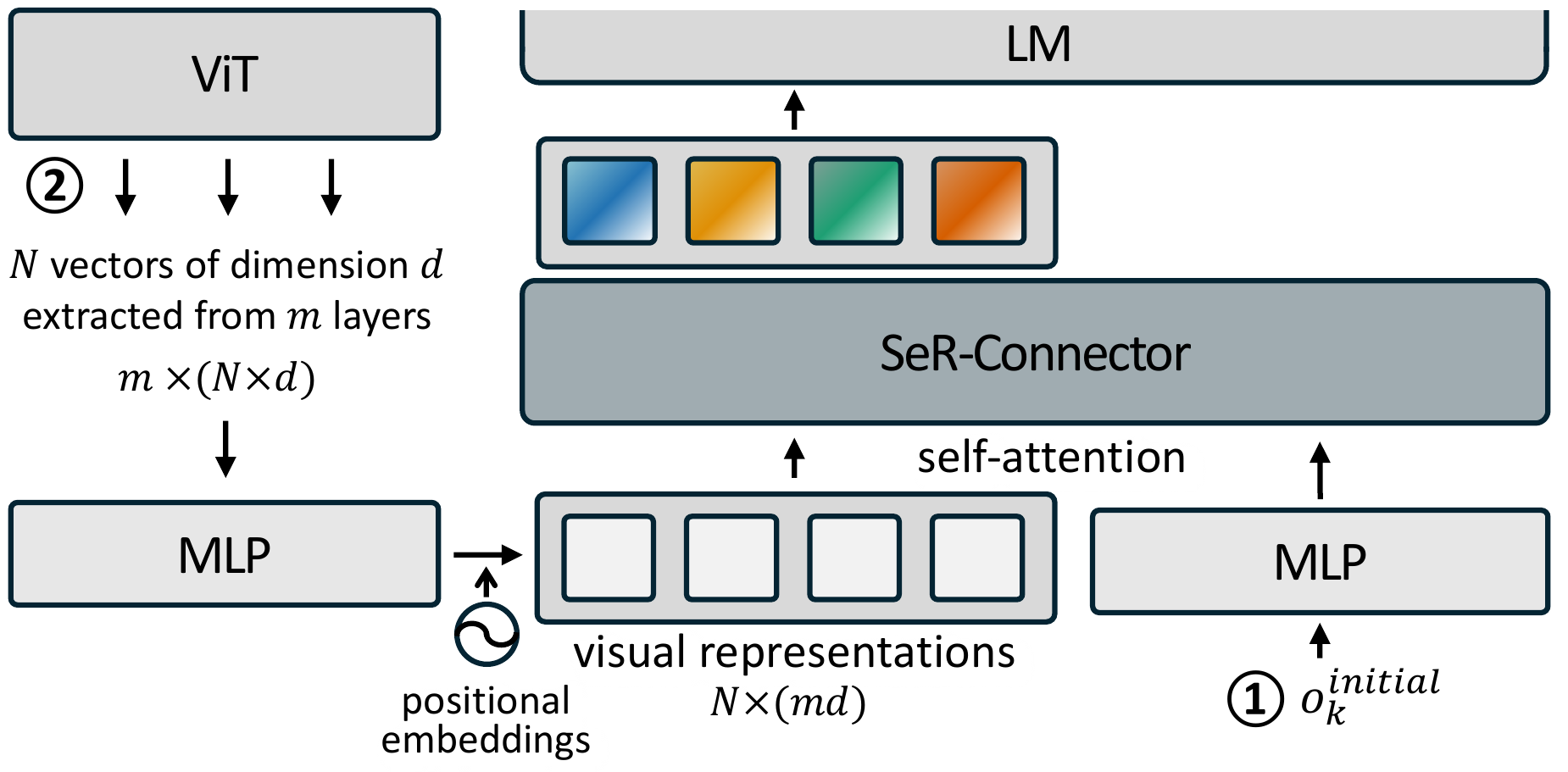
1
Detailed Captioning
ShareGPT4V & DCI
Initial
+ MM-SeR
MM-SeR consistently improves CIDEr, CAPT, CLAIR, and GPT evals, demonstrating the effectiveness of our framework in improving caption quality.
